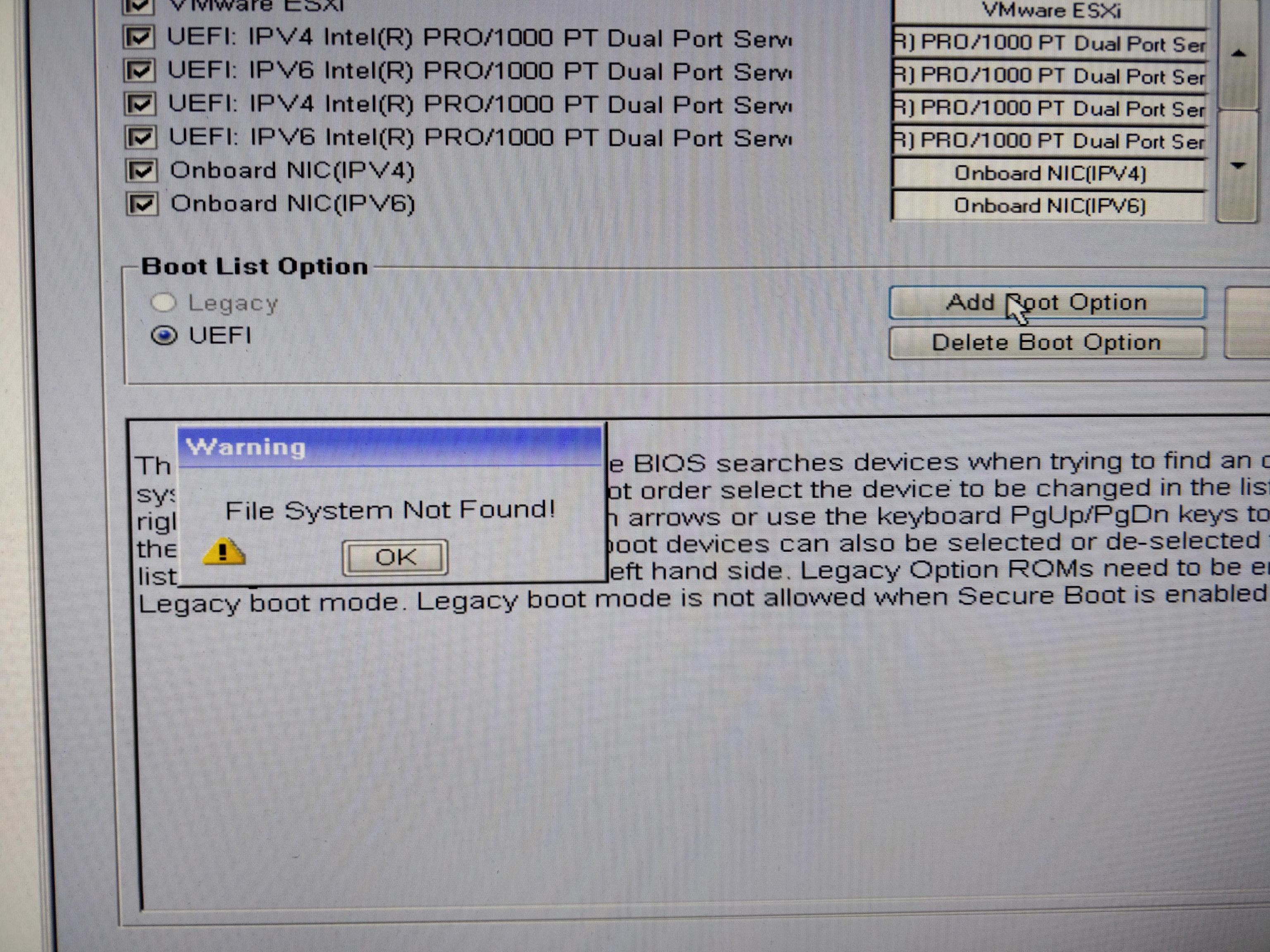
Now the details. After performing vSphere installation and booting the system, the UEFI boot menu would contain “VMware ESXi” entry. Selecting the entry would result in no response. VMware has an article suggesting a possible solution, which did not work in my case. All attempts to manually add a new boot entry in BIOS resulted in “File system not found” error.
So, I thought maybe filesystem on EFI partition is not clean. I booted the machine using USB stick and ran fsck on the partition:
root@mint:~# fsck /dev/sda1
fsck from util-linux 2.31.1
fsck.fat 4.1 (2017-01-24)
/dev/sda1: 11 files, 348/51091 clusters
root@mint:~#
Filesystem was clean, yet the machine failed to boot. After some searching I found a similar problem. Again, I tried the filesystem check, this time using FreeBSD:
# fsck_msdosfs /dev/da0s1
** /dev/da0s1
** Phase 1 - Read FAT and checking connectivity
** Phase 2 - Checking Directories
** Phase 3 - Checking for Lost Files
Next free cluster in FSInfo block (2) not free
Fix? [yn] y
4 files. 31MiB free (63781 clusters)
#
It seemed the filesystem check fixed an issue. Still the machine would not boot. The only thing I had not tried at this point was to recreate FAT filesystem on vSphere EFI partition…
root@mint:~# mount /dev/sda1 /tmp/EFIMNT/
root@mint:~# cp -r /tmp/EFIMNT/* /tmp/EFIBKP/
root@mint:~# umount /dev/sda1
root@mint:~# file -s /dev/sda1
/dev/sda1: DOS/MBR boot sector, code offset 0x58+2, OEM-ID "MSDOS5.0", sectors/cluster 4, reserved sectors 2, root entries 512, Media descriptor 0xf8, sectors/FAT 200, sectors/track 32, heads 64, sectors 204800 (volumes > 32 MB), serial number 0x558938bd, label: "BOOT ", FAT (16 bit)
root@mint:~# mkfs -t vfat -n BOOT /dev/sda1
mkfs.fat 4.1 (2017-01-24)
root@mint:~#
…then check the new filesystem and put back the original boot files:
root@mint:~# file -s /dev/sda1
/dev/sda1: DOS/MBR boot sector, code offset 0x3c+2, OEM-ID "mkfs.fat", sectors/cluster 4, reserved sectors 4, root entries 512, Media descriptor 0xf8, sectors/FAT 200, sectors/track 32, heads 64, hidden sectors 64, sectors 204800 (volumes > 32 MB), serial number 0x31d4d250, label: "BOOT ", FAT (16 bit)
root@mint:~# mount /dev/sda1 /tmp/EFIMNT/
root@mint:~# cp -r /tmp/EFIBKP/* /tmp/EFIMNT/
root@mint:~# umount /dev/sda1
Finally, the machine booted. I retried the whole process a few times. Above was the only time when FreeBSD fsck returned with unclean filesystem. So, I am not entirely sure, if vSphere 8 has some thing going on, or if it is the fact that my Dell Optiplex is so old. Nevertheless vSphere 8 was successfully installed.
]]>